Les enjeux du HPC et la préparation à l'exascale
L’enjeu des machines accélérées
Avec la fin de la loi de Moore, la performance des calculateurs augmente en agrégeant de plus en plus de cœurs, le plus souvent accompagnés de cartes graphiques (GPU) capables d’accélérer les boucles de calcul. En France, après l’IDRIS, le CINES accueille une machine composée majoritairement d’accélérateurs GPU, Adastra, dont la performance crête atteint 70 PFLOPS. Le projet Exascale France vise à équiper le centre du TGCC d’une machine exaflopique pour laquelle l’essentiel de la puissance crête proviendra d’accélérateurs GPU, dont la technologie reste encore à définir.
Ces cartes graphiques intègrent des milliers de petites unités calculs très efficaces pour traiter simultanément une même instruction sur un gros volume de données comme c’est le cas des calculs opérés par des boucles imbriquées (kernels de calcul). Ces dernières sont alors transférées (offload) du CPU (host) vers le GPU qui effectuera les calculs. Cependant, les performances chutent dès lors que trop de données sont transférées entre CPU et GPU, en raison de la latence et de la faible bande passante du bus d’interconnexion. Il est alors nécessaire de minimiser ces transferts en gardant au maximum les données sur le GPU. De ce fait, la programmation devient plus complexe.
Plusieurs approches sont possibles pour porter des codes sur GPU, allant des langages de bas niveau très intrusifs (i.e. CUDA, OpenCL, HIP), à des approches moins invasives à base de directives comme par exemple les standards ouverts openACC et OpenMP5. Pour certains codes, la réécriture complète est envisagée en s’appuyant sur des concepts faisant la séparation entre le contenu du code (équations physiques) et son exécution sur une architecture spécifique, à l’aide d’une couche d’abstraction (separation of concern), mettant en œuvre, soit des librairies de plus haut niveau (Kokkos, Raja, SYCL,…) qui pour la plupart nécessite un code écrit en C++ moderne, soit des langages dédiés à un domaine particulier (Domain Specific Language, DSL) pour le climat et la prévision du temps (PSyclone, GridTools).
A l’IPSL, le nouveau cœur dynamique DYNAMICO a été porté en 2019 sur GPU dans le cadre du contrat de progrès de l’IDRIS (3 mois de travail pour 3 personnes). Dans ce cas précis, les résultats montrent que pour un même temps d’exécution, un GPU (NVidia V100) est 4 à 6 fois plus rapide qu’un processeur CPU Intel de même génération (Cascade Lake), suivant la résolution spatiale (pour respectivement 200 km et 12 km). Cependant, lorsque que l'on effectue des calculs parallèles sur plusieurs nœuds, l’efficacité des GPUs sature plus rapidement que celle des CPUs, car les GPUs deviennent sous alimentés en calculs pour exprimer leur plein potentiel alors qu’au contraire les CPUs deviennent plus efficaces en bénéficiant des effets de caches liés à la diminution du volume de données traitées par cœurs. On se retrouve donc avec de meilleurs temps de restitution en faveur des CPUs (voir la figure). 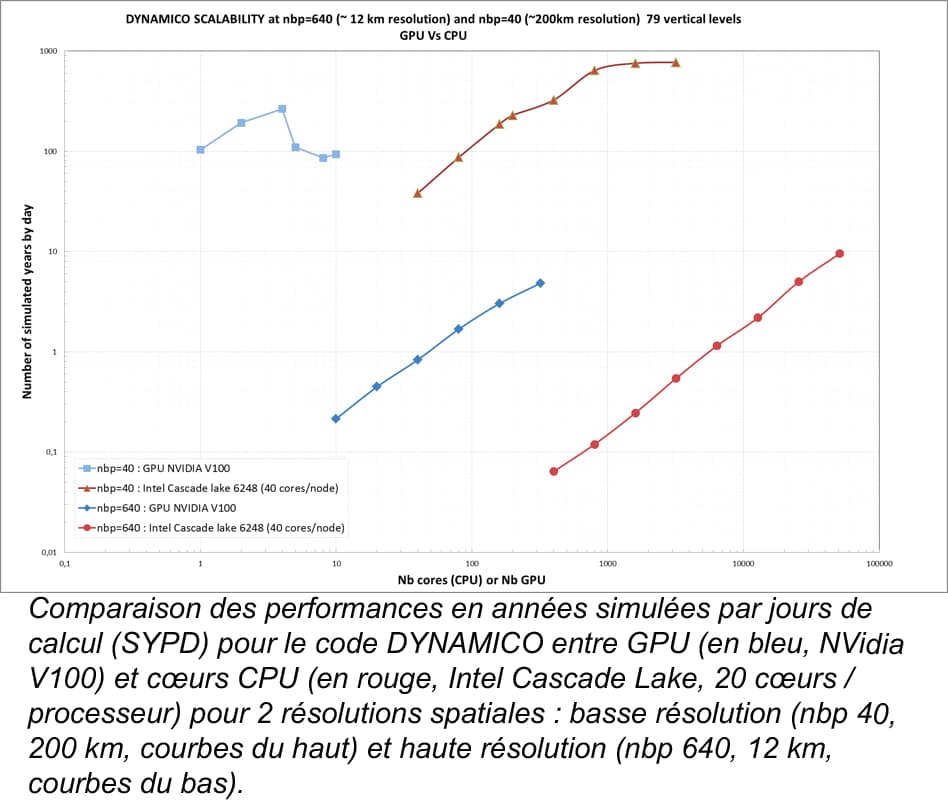
Néanmoins, il faut contrebalancer ce résultat en considérant le coût intégré (matériel + énergie) des 2 solutions pour un temps de restitution équivalent. En effet le rapport flop/watt est très en faveur des GPUs, mais leur coût d’achat est plus élevé, d’autant qu’en général, sur un nœud GPU sont également présents au moins 2 CPUs. Toutefois, on constate d’ores et déjà que l’efficacité des GPU est mieux exploitée à haute résolution, écart qui s’accentuera probablement avec les générations futures. Plus récemment, ce retour d’expérience a été confirmé lors de la participation en 2021 d’une équipe du LMD-IPSL à un hackathon organisé par l’IDRIS à partir d’une version simplifiée de la physique du modèle d’atmosphère, pour laquelle on obtient des résultats du même ordre.
Passer au portage sur GPU de l’ensemble du modèle couplé de l’IPSL qui comporte plusieurs codes, un plus grand nombre de lignes de codes, et des échanges importants de données, est un enjeu d’envergure. En effet, pour DYNAMICO ou la physique simplifiée, l’effort de portage n’a concerné que quelques milliers de lignes, qui sont à comparer aux près de 500 000 lignes composant l’ensemble du modèle couplé. Ce portage est d’autant plus complexe que nos modèles ont un profil de performance relativement plat, c’est-à-dire que le temps de calcul n’est pas dominé par une petite partie du code sur laquelle l’effort pourrait se concentrer. Cette adaptation des codes nécessitera également de repenser totalement l’architecture logicielle. Néanmoins cet effort est absolument nécessaire pour la réalisation de simulations à plus haute résolution ainsi et/ou de grands ensembles, car il est acté que l’essentiel de la puissance disponible des prochains super-calculateurs proviendra des accélérateurs. Le projet PEPR TRACCS va apporter un soutien important pour aborder cet enjeu.
Rédacteur : Y. Meurdesoif (LSCE-IPSL)
En savoir plus
- Pour accéder à tous les articles de la e-Lettre N°3, cliquer ici
- Pour obtenir la version imprimable de la e-Lettre N°3, cliquer sur l'image
